Мифы и легенды разработки ПО. Том первый.
Шучу, на настоящее многотомное «собрание сочинений» меня просто не хватит. Так что ниже лишь очень небольшая часть — самые популярные мифы и легенды разработки ПО, «техноересь», которую приходится постоянно искоренять в реальных проектах.

Каждая профессия имеет свою мифологию и свои легенды, самые популярные из которых «уходят в народ» и становятся широко известны далеко за пределами профессиональной тусовки.
У врачей например так появился «миф о дисбактериозе», давно ушедший в народ благодаря популяризаторам и борцам с лженаукой и «фуфломицинами».
Казалось бы у технарей-программистов не может быть никаких профессиональных мифов, как и веры в «сверхестественное» и магическое — не за тем они получали высшее техническое образование, верно?
Увы но нет, как показывает практика магическое мышление совершенно спокойно уживается в одной голове с инженерным образованием, безо всяких диссонансов.
Миф первый: мой софт быстрее твоего
Сам термин «скорость» уже настолько потерял всякий технический смысл, что скоро за его использование будут бить лицо перестанут уважать даже современные дети, которые (внезапно) знают что такое FPS и ping — целых две актуальных метрики, серьезно влияющие на ту самую «скорость работы».
Поэтому никакой софт не задумывается и не создается медленным, но бывает «приемлемо быстрым» — когда считается что скорости работы достаточно для решаемых задач.
Есть такой жирный корпоративный бегемот Oracle Weblogic — сервер приложений и платформа для работы еще более жирных и страшных корпоративных решений.
Один только холодный запуск этого монстра может занимать несколько минут. И это считается приемлемым, поскольку Weblogic это софт для больших компаний, созданный для работы внутри большой корпоративной сети — с кучей сетевых ресурсов, к которым ему нужно подключиться при старте до начала работы.
Еще ни в одной компании на свете нет и не может быть 50 миллионов сотрудников, не говоря уже о миллиардах, тем более работающих одновременно в одной корпоративной системе. Поэтому принципы построения высоконагруженных систем не особо используются для корпоративной разработки.
весь корпоративный софт масштабируется только до предела, который был заложен его разработчиками.
И это тоже считается приемлемым, потому что корпоративный софт это четко выверенная середина и баланс между стоимостью разработки, стоимостью владения и скоростью работы.
Еще и с разными ценниками для разного масштаба внедрения.

Миф второй: только дебилы пишут на [вставьте название]
Так исторически сложилось что большинство занятых в разработке ПО людей являются самоучками, не имеющими ни профильного образования ни кругозора ни даже особого интереса к «чужим» областям знаний.
Начиная с первых подработок во время обучения и далее на постоянной работе у типичного программиста происходит фиксация и погружение в какую-то одну экосистему разработки, выстроенную вокруг одного ключевого языка.
- Java, JakartaEE, Maven, Spring, Hibernate — классический Java-стек;
- C#, .NET, ASP.NET, EF, Angular — набор современного дотнетчика;
- Swift, Objective-C, iOS, Xcode
и чулочки— для разработки под Mac и iOS.
Лишь очень немногие разработчики имеют достаточно мотивации чтобы вылезти за пределы своего болота единожды выбранного стека, тем более свободно владеть несколькими разными.
Поэтому у большинства представителей профессии проявляется сильно искаженный взгляд на мир:
за МКАДом жизни нет. Там ад и ходят люди с песьими головами.
Отсюда и весь негатив по отношению к «чуждым» языкам и технологиям — банальное невежество, пополам с самомнением.

Миф третий: мой паттерн "православнее"
Существует отдельная каста шизов от разработки, которые считают каждый паттерн проектирования прямым руководством к действию а показанную в очередной книге по паттернам реализацию неким святым эталоном, отступать от которого — ересь и святотатство.
По неведомым причинам, самые лютые «паттернопоклонники» происходят из читателей Джошуа Блоха, видимо потому что его книги по своей структуре сильно напоминают религиозную литературу.
Для всех таких шизов объясняю (хотя конечно не поможет):
Ни ритуальные оргии с жертвоприношениями, ни групповое чтение вслух, ни зубрежка наизусть при свечах, ни даже дословное воспроизведение в ваших проектах — не работают для технического материала.
Вы можете обчитаться книжками Лавкрафта и начать поклоняться «подводным богам», это даже в некоторой степени нормально, ничем не хуже обычной религиозной секты.
Но блин нельзя на серьезных щщах славить «закон Ома» и считать «Основы термодинамики» Н.В. Карякина религиозной литературой, разбирая и заучивая каждый абзац — техническая документация так не работает.
И именно такой шизой занимаются «паттернопоклонники», пытась перекроить доверенные проекты согласно неким одобренным их «божеством» паттернам проектирования.
Если бы софт можно было создавать только по готовым паттернам — такого количества программистов просто бы не существовало, а сам процесс был куда проще, быстрее и предсказуемее.

Миф четвертый: ORM не нужны
Допустим есть база данных с записями, к которой подключено клиентское приложение, оперирующее объектами.
Для упрощения связывания записей в базе с объектами в приложении как раз и существуют ORM — специальные библиотеки-прослойки, берущие на себя задачу подобного связывания и поэтому управляющие всей логикой получения и изменения данных.
Технология ORM (Object-relational мapping) — штука сложная и капризная, требующая соблюдения определенных правил по организации приложения и его внутренней логике.
Разумеется что технология, являющаяся лишь прослойкой по своей сути и при этом требующая изучения — мягко говоря не вызывает восторгов у начинающих разработчиков, поэтому они при любой возможности стараются от нее избавиться.
Порождая в итоге проблемы такой сложности, что поправить подобный проект возможно только с привлечением очень опытных разработчиков.
Если вы тоже не любите ORM и считаете его говном ненужной прослойкой — задумайтесь (а лучше протестируйте) что будет происходить в вашей системе когда десяток пользователей начнут производить одновременную правку одних и тех же данных — например обновлять карточку клиента в вашей CRM.
Думаю вас ожидает сюрприз и последующее долгое изучение матчасти про «pessimistic/optimistic locking» и работу транзакций.
Миф пятый: реляционные СУБД устарели, не надо их использовать
Ввиду возраста я застал весь процесс появления, развития и перехода в зрелость т. н. NoSQL решений, которые сразу позиционировали себя не меньше чем «убийцы SQL» и реляционной модели.
На примере флагманского проекта всей NoSQL-тусовки — MongoDb отлично прослеживается весь этот путь, который привел их и к отдельному языку запросов сильно похожему на SQL и к нормализации и даже JOIN-ы в конце-концов появились.
Итогом прогресса явилось нечто очень и очень близкое к обычной реляционной СУБД, а вся разница ныне заключается лишь в используемой терминологии («коллекция не таблица, Куба — не заграница») и соблюдении стандартов.
Вообщем все что вы должны знать о реляционных СУБД это тот факт, что под ними лежит глубокая научная база, а не известное «batteries included».
Сам язык запросов SQL был придуман не студентами-школьниками и даже не хипстерами, попивающими смузи на пляже, а серьезными академиками в результате долгих научных изысканий.
Существует даже знаменитый курс в Беркли с номером CS 186, посвященный имплементации реляционной СУБД с нуля, как раз на описанной выше научной базе.
Вот так например выглядит одно из домашних заданий на гитхабе, которое я использовал для обучения.
Кстати если у вас телефон на Android, в нем также используется встроенная реляционная СУБД SQLite, она же используется для локального хранения сообщений в Telegram.
Словом реляционные СУБД это нечто больше чем отдельное решение, это концепция, которая давно оправдала на деле и свою «чрезмерную сложность» и все нерешаемые проблемы с производительностью и масштабируемостью — все те аргументы что постоянно используют ее противники.
И переживет эта концепция и вас и меня, поверьте.

Миф шестой: веб-технологии не нужны
Да, такие идеи тоже живут в головах разработчиков в 21 веке, которые даже не стесняются их высказывать в соцсетях с помощью «ненужных» веб-технологий.
Обычно это «вой из подвала» где сидят backend-разработчики или «железячники» — тенесчастныекто занимается программированием под железо и встаиваемые системы. Еще временами к ним присоединяется геймдев и редкие представители desktop-разработки, которых еще не сократили за ненужностью.
Суть их претензий в том что современный веб устроен чрезмерно сложно, отчего все связанные технологии также переусложнены. Поэтому их применения стоит избегать всегда и везде и всеми возможными способами.
И с технической точки зрения такие заявления действительно обоснованы — веб до сих пор активно развивается, поэтому развивается и веб-разработка, причем огромными темпами.
Веб-разработка сейчас является локомотивом всей ИТ-индустрии, именно в ней задействовано больше всего разработчиков и для нее активно создаются все новые и новые инструменты, языки и технологии.
Поэтому очевидно что в обычных проектах, не имеющих задачи обкатки всего самого нового и интересного обязательно будет техническое отставание от мейнстрима.
И это нормально и предсказуемо.
Но не повод полностью отказываться от веба вообще, на что тоже есть серьезные причины.
Допустим вы ударились в архаику и сделали чистое desktop-приложение — современный графический редактор, дающий ваять шедевры с помощью нейросети.
Следующий же этап развития потребует интеграции с вебом: маркетплейс с расширениями, настройка оплаты, личный кабинет, авторизация через социальные сети и тд и тп — наличие такого функционала ныне подразумевается даже у desktop-приложений.
О чем вообще можно говорить, когда даже экран блокировки в Windows теперь показывает виджет с погодой на основе веб-технологий.

Миф седьмой: свои серверы не нужны, все уходят в облака
Очередной радикальный миф, в этот раз от современных «хипстеров-смузихлебов», считающих что их работа заканчивается на коммите в репозиторий с исходным кодом, а как оно там работает в продакшне пусть лучше разбирается Гугл с Амазоном — им виднее.
Если вся ваша разработка это лендинги и сайты-визитки с простейшей обработкой данных — вопросов нет.
Как говорится «вставляй и наслаждайся», в облачном борделе рады любым клиентам.
Но все что хоть немного сложнее лендинга немедленно порождает серьезные вопросы:
- Кто и на каких условиях отвечает за ваши данные в облаке?
- Кто гарантирует совместимость вашего ПО в облаке на период в 3-5 лет?
- Кто именно отвечает за сбои и восстановления в облаке?
- На каких условиях возможно прекращение предоставления услуг?
И внезапно оказывается что облачное размещение это просто массовый сервис, в котором никаких индивидуальных гарантий не предусмотрено — модель бизнеса такая.
Разумеется облачный сервис «в среднем» надежнее и обслуживается более серьезными специалистами чем вы сможете нанять, но из-за массовости предоставляемой услуги, конкретно вы как клиент такого сервиса, с вашими данными и запросами — нахер никому не нужны.
Если ваши данные повредят при миграции, удалят или украдут — никто со стороны сервиса за это отвечать не будет.
Я еще не упоминал про разрыв договора на обслуживание «в одностороннем порядке и без объяснений»?
Миф восьмой: Boilerplate не нужны
Продвинутый миф, для продвинутых поцанов разработчиков, кто вообще знает что это такое:
Boilerplate — готовый шаблон проекта, который используется в качестве каркаса для дальнейшей разработки.
Классические примеры: JHipster, ASPBoilerplate, SwiftShip.
Суть претензий в том что применяются такие шаблоны якобы только из-за тупости отсутствия компетенций — нехватает знаний для разработки с нуля.
И заодно они являются признаком дурного вкуса, поскольку с таким шаблоном в будущий проект затягивается огромное количество ненужного кода, который потом придется поддерживать долгими ночами.
Реальность же как обычно несколько отличается:
готовый шаблон проекта очень сильно ускоряет начальную разработку.
Вместо условно месяца ручной работы с помощью такого шаблона подготовка занимает лишь несколько часов.
Сколько это в деньгах думаю сами оцените, поискав в интернете стоимость часа времени разработчика.
После такого думаю какие-то дополнительные аргументы не особо нужны, но все же добавлю еще одну чисто техническую причину для использования шаблона а не ручной разработки.
Совместимость отдельных библиотек — можно очень быстро утонуть в деталях, дойдя до разгребания коммитов в исходный код каждой библиотеки если идти путем полностью ручной сборки шаблона на начальной стадии.
Например самая популярная связка в Java из Spring + Hibernate имеет четкие границы совместимости:
конкретные версии Spring Data совместимы с конкретной версией Hibernate, который совместим с конкретной версией Hibernate Search, который совместим с конкретной версией Lucene.
И таких связок в реальных проектах очень много, выяснять границы совместимости между библиотеками методом тыка — так себе развлечение.

Миф девятый: XML устарел, JSON — новое светлое будущее
Суть очередной претензии «от юных к старшим» в том что старый добрый формат XML — избыточен, занимает много места, неудобен для ручной правки и вообще не радует глаз пионера.
И все это действительно правда, но только есть нюанс:
Это так и было задумано изначально, ради дополнительного контроля целостности данных и более быстрого поиска по ним (да да тот самый XPath).
Допустим есть вот такой XML-документ:
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
</catalog> Чтобы испортить этот документ в процессе работы, допустив его частичную обработку, придется как минимум полностью сохранить структуру:
<catalog> <book/> </catalog>
Поскольку главным признаком валидности XML-документа является полное соответствие и порядок открываемых и закрываемых тегов.
Что на практике сделать практически невозможно, поэтому любой сбой обработки XML будет виден сразу и явно — путем выбрасывания явной ошибки.
Теперь посмотрим на аналог документа выше, но в виде JSON:
{
"catalog" : [{
"id" : "bk101",
"author" : "Gambardella, Matthew",
"title" : "XML Developer's Guide",
"genre" : "Computer",
"price" : "44.95",
"publish_date" : "2000-10-01",
"description" : "An in-depth look at creating applications with XML."
}]
}Какие варианты c порчей данных будут успешно обработаны?
{}{ "catalog" : [] }{ "catalog" : [{}] }Все это - абсолютно валидные документы JSON, который спокойно пройдут десериализацию и превратятся в пустой DTO-объект. И вот уже там будет происходить валидация на обязательность полей.
Но это еще не самое веселое, взгляните:
{
"catalog" : [{
"id" : "bk101",
"author" : "Gambardella, Ma"},{ "xx": "tthew",
"title" : "XML Developer's Guide",
"genre" : "Computer",
"price" : "44.95",
"publish_date" : "2000-10-01",
"description" : "An in-depth look at creating applications with XML."
}]
}Как думаете что случится при обработке такого документа?
Он будет обработан, более того — он пройдет любую валидацию:
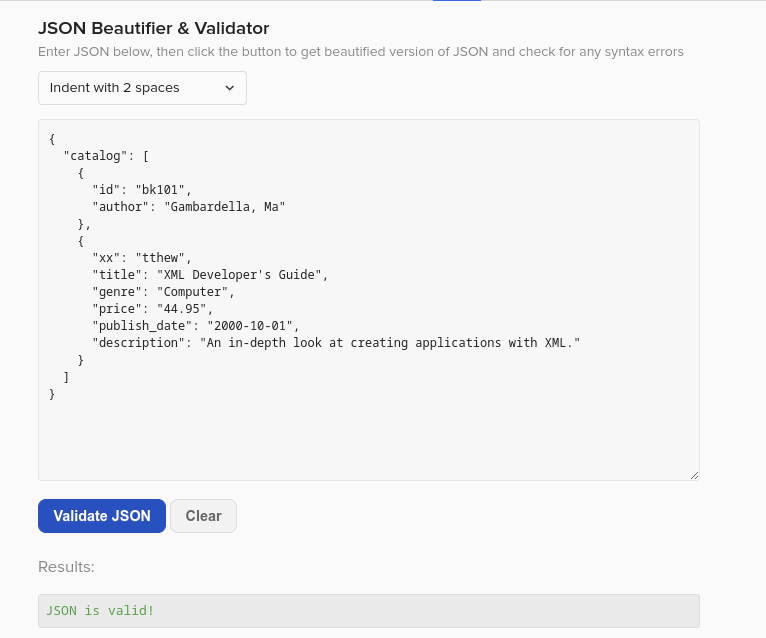
Теперь представьте что внутри информация о банковской транзакции а таким нехитрым способом подменили счет получателя.